I am really behind on my blog posts, but here is a random one that wasn’t actually on the backlog.
I have been using the Seek app quite a bit while wandering the fields near where I live during lockdown. This is a project to visually identify all species through an app that is based on a large open data set and models. It does an amazingly good job, only very occasionally making mistakes like identifying a diving duck briefly as a crocodile; more often it gets stuck at the genus level and finding the species a little too hard which is forgivable. Definitely recommended to make wandering around more interesting, it will link to interesting things about how species arrived, and things about them that you didn’t know from Wikipedia as well. And it is fascinating to be able to walk along paths you have been on many times before and still find a dozen new species.
The more complex a plant is, the more parasites and attackers it has. But two species, the rose and the oak, seem to have the most interesting attackers of all. I saw this mossy ball one day and was surprised when Seek told me it was a wasp, I mean it looks like a plant. So what is it?
In computer security we use biological metaphors such as “antivirus” but the complexity of the natural world really shows us what a complex attacker ecosystem looks like. This is a gall, from the gall wasp species Diplolepis rosae. It is traditionally known in the UK as Robin’s pincushion, and more formally as the rose bedeguar gall or mossy rose gall. The gall wasp female lays eggs in the leaf bud of the rose, and these eggs, and later the larvae that hatch from them, manipulate the plant into growing the gall around it. This is why it looks like a plant like structure, as indeed it is, but not a normal one. In particular, the gall provides highly nutritious plant cells for the wasp larvae to eat, with the plant transporting nutrients directly to the gall for it to eat. It grows in weird ways, but using the host plants genetic material, manipulated by the wasp in ways that are not yet understood.
This is exactly the mechanism of weird machines in computer security, where “the implicit data flow and the subsequent transfer of control were performed by the program’s own code, borrowed by the exploit for its own purposes.” The attacker takes gadgets and existing code fragments and applies them in unexpected, unplanned for, weird ways to make the code do things that were not intended by the author, indeed things that are totally outside the designed scope. “Borrowed pieces of code could be strung together, the hijacked control flow linking them powered by their own effects with the right crafted data arranged for each piece.”
Gall wasps are widespread, and each species produces a different type of gall, by attacking the plant in a different way. But roses and oaks seem to be the main hosts. Around where I live these particular rose species are very common, found on a lot of the wild roses. There are also several kinds of oak gall wasp around.
It turns out that the galls themselves allow complex attacker communities to thrive. Other species of wasp live in the comfortable gall habitat. In general the other species are not parasitic on the gall wasps, as only these have the ability to keep attacking the host rose to keep the flow of nutrients coming. But other wasp species lay eggs in the same place a little later to also live in the same habitat, and indeed can only live in these places, a lifecycle known as “inquiline”. There are parasites on the inquilines, and a complex community of attackers; the majority of the wasps that hatch out the next year will not be the original species that caused the gall. The gall is itself easier to attack than the plant, because of how it has been manipulated into a softer mass.
Another random fact about the Diplolepis rosae wasp is that almost all of them are female. This is actually in itself due to a bacterial infection of the gametes, with the bacteria manipulating the wasp so it only produces female eggs.
One of the interesting things about computer security is that we are only just starting to see the structure of attacks and defence. The natural world has so many different attack and defence mechanisms that are worth exploring to see what happens when things are subverted in novel ways, or have different types of defence, or little defence at all. Or you can just wander around and learn about the amazing natural world.
The other day I got a message from Jenny “the Burce” saying that I had to get
some equipment to upgrade my live streaming setup for the DockerCon dry run.
Cameras and microphone and things, a list from Bret
Fisher. Only problem, I soon discovered, was that
nothing on the list was actually available. Somehow just after lockdown
everything that people might need to live stream audio and video had been panic
bought, along with the flour, toilet paper and eggs. So over the next month or
so I have gradually put together a setup that works, with the aim of improving
the audio and video quality.
It has also been the first time I have worked at home for long periods,
previously I mostly went to the office with a few meetings at home at the start
and end of the day. Given that we are all going to be homeworking for a long
period, may as well make it better. Due to lack of availability all the low end
stuff was unavailable, but will give some pointers and suggestions as to what
is worthwhile or not, and supply chains should start to improve soon. I am
lucky enough to have a reasonable amount of space, if you are working in a
constrained space I would imagine choices are more limited.
Also I am lucky enough to be able to work at home, or at all in these difficult
times. Tech workers are so lucky and safe compared to so many others.
Desk
1970s Danish teak desk, bought on the Holloway Road some years back. Not in
perfect condition or anything, a desk for using. Hard to move around. Big, not
going to fit in a small space. I don’t remember the price, it wasn’t a lot and
it will last another 40 years. The lamp is a German, asymmetric one from the
1930s.
Computer
MacBook Pro from a few years back. I have been wondering about getting a
desktop as, well, not going anywhere. However I want something silent and that
seems really difficult now. I do have a Linux box (carefully constructed with
large slow fans) and a FreeBSD FreeNAS box under the table, but although they
are fairly quiet I find them too noisy when working so I mostly keep them
switched off. The cloud is silent of course, a great advantage. I may go down
the silent PC building route again soon, will keep you posted.
Monitor
Dell 27 inch 4k monitor I took from the office. I thought it was too small on
this desk, but then realised I had it too far back. I would probably get a USB
C monitor now, just to get more ports nearby but this is fine. I don’t like
double monitors due to the gap, I prefer a single large one.
Internet connection
It is going to be difficult to improve quality for live conversations without a
good internet connection. Obviously there may not be much choice where you are
though, so changing this can be difficult. I use Andrews and
Arnold with 80/20Mbs VDSL; they are a high quality
service with static IPs, IPv6, and they do not have oversubscription. It costs
a bit more than other providers.
Keyboard and trackpad
Need cleaning. Apple bluetooth ones. I also have a (noisy) Hacker’s keyboard
around. I much prefer trackpads to mice or trackballs now.
Dock
Realising I was about to plug in more things than the computer has ports, I got
the Caldigit TS3 Plus as recommended by
someone on Twitter. This provides power down one thunderbolt cable to the
computer, while having everything else plug into it. It has displayport for the
monitor, and wired ethernet, meaning I can avoid wifi issues. The wired
ethernet goes via ethernet over mains adaptors downstairs to the router. Note
that if you have the new MacBook Pro 16 inch, this consumes a peak 97W of power
which is more than this delivers although maybe there will be a firmware fix.
CPU peak power consumption is getting ridiculous now, 100W laptops!
Webcam
I managed to order a Logitech
StreamCam direct from
Logitech just before all webcams sold out. It is excellent quality, see
pictures below. I sit it on top of the monitor, and it has USB C. It has a very
wide angle of view, but I eventually found out that the Logitech Camera
Settings App allows you to modify this, with a narrower setting too. This is
just a crop, so it is not as high quality. The Logitech software is much worse
on Mac than Windows it seems, with far less control available; some of the
Windows controls appear to be done in software with a software video out that
other applications can connect to which is not available on Mac. The Logitech
4k cameras apparently have three zoom options as well as ability to set frame
rates, and it looks like some stock may become available again, so these could
be better for a cropped view. Actually using the 4k option is not really
possible with most software at present though, and it requires lots of CPU to
encode.
Having the camera above you on the monitor is way better than using the camera
on a laptop, which is generally low down unless you raise it up a lot; also as
you want to use a monitor generally the laptop is probably to the side, which
looks strange on calls. I don’t know why Apple do not improve the quality of
laptop cameras to match their phone cameras, and I have heard of people using
phones to stream.
Another option a friend is exploring is using a digital camera; most recent
cameras can stream video although generally only via HDMI out so you need
something like the Elgato Cam
Link and these are also hard to
get now. With a choice of lenses and zoom and excellentpicture quality this is
an option if you already have a suitable camera; you probably want to use a
lens around 35mm it seems. You will need to mount it behind the monitor which
needs some work. Obviously this is a substantially more expensive option and
only makes sense if you have a camera already for other uses.
Lighting
Cameras are way better quality with lights. You might not immediately notice,
so here are some crops to give you an idea of low light versus a reasonable
light. I have the Elgato Key
Light, which is wifi controlled.
You probably need something this bright, I had a small LED panel and it was not
bright enough.
The pictures below show crops of the video in the dark without lighting, with
light from the window only and lit with additional lighting.
The Key Light has a slightly annoying property of occasionally losing wifi
access and needing to be reset, although it stays on during this time, so I am
not sure I can entirely recommend it, although it hasn’t happened for a while
now. It is also expensive, but generally good. Lights are difficult to
buy. This clamps to the table which is good, as tripod type stands take up
loads of desk space or floor space around.
I also have a window to the side, which provides most of the light during the
day, but I use the light at a lower level as a fill light, or else the side of
my face away from the window is very dark. At night I use the light as a key
light, and don’t use a fill, so it is a bit like Rembrandt lighting. Look at
three-point lighting to
get an idea of how to place lights, you ideally want them diagonally
notdirectly in front, or else it looks very flat. I place the webcam a little
bit asymmetrically pointing into the room so it does not catch the very bright
window. The worst setup is if you have a window behind you, when the camera
will have a hard time, as you can see when having calls with people with that
setup.
Audio
Audio gets complicated very fast. Your options are to use your laptop, or to
use the microphone on your webcam, which is what I was doing for a while, and
still do sometimes. There is another problem though about how to listen to the
audio, and avoiding the microphone picking up the sound of the other party, or
yourself. I had a bias towards audio/music equipment as I have used it in the
past a little and it is currently relatively easily available; there are very
different routes you could take here.
The original recommendation from Bret was to get the Samson
Q2U,
but this remains totally unobtainable. Actually all USB microphones were
unobtainable. If you get a USB dynamic microphone, such as the Q2U or the
Audio Technica ATR2100 which is
similar but more expensive (but maybe available now) then your route will be
simpler and cheaper than mine below.
So I went the traditional route. Generally the advice seemed to be that unless
your room is a soundproofed studio, get a dynamic microphone not a condenser
microphone, as they are more directional and likely to mostly pick up your
voice not what is going on outside or downstairs or even the noise from your
keyboard. I went for the classic Shure
SM57 a microphone that
has been around so long it has its own Wikipedia
page and White House
stories. I ordered direct from the manufacturer which was very
quick; apparently there are a lot of fakes of these so it is worth buying from
a reputable place. You can’t see it clearly in the photo above as it is pointing
straight at me, as I am sitting it does not obstruct the view, but I can move
it away andback on the mic stand, see below.
As the mic has XLR analogue outputs you need to plug it into the computer. The
easiest way is to get an audio interface, that combines a microphone pre-amp
and an analogue to digital converter. I got the Audient
EVO4, which seems really nice and
excellent quality. Audient is a UK company that makes mixers and other
professional audio recording hardware; this is their “diffusion line” but has
the same high quality hardware. This also acts as a headphone amp, and can live
mix the audio from the mic into the headphone so you can listen to yourself
speaking. It supports two mics, or a mic and an instrument, and there is also a
four channel version, for a future world without social distancing when we are
in the same room again. There is only one potential issue with this
combination, which is that the microphone outputs at a very low level. The EVO4
has 58dB gain, which is quite a bit more than most units I looked at, but if
you have a quiet normal speaking voice and don’t project it, even if you have
the gain set to maximum, if you speak more than around two inches away from the
mic it is a little quieter than ideal. At around two inches away it is fine
although with some extra bass emphasis, or if you speak up a bit, but I am not
really used to doing either of those most of the time on calls. I should
probably get used to it; the
recommendation is to be less than
15cm away.
I ended up, in the spirit of testing every option, getting a
FetHead which is a tiny microphone
preamp that fits inline with the mic and provides an additional 27dB of gain,
powered from the preamp. This is designed for exactly this use case with
dynamic microphones. Adding it suddenly shifted from having to use max gain at
all times to being in the middle of the scale and having plenty of room to
adjust. It also cut the small low noise level even lower. I would say if your
preamp has less than 58dB of gain you would need this with this mic, otherwise
you could get away without it but it gives a little more flexibility. I chose
the EVO4 partly due to the fact it has relatively high gain, so you would get
more choice with the FetHead as any audio interface will be fine, although the
Evo4 is still a nice choice I think.
Usually you are recommended to use headphones for audio recording, so as not to
record the output sounds along with input. Much software has echo cancellation
built in, and the Mac has some hardware cancellation, although that may just be
on the built in microphone and speakers. This means that you don’t necessarily
need to wear headphones for many use cases, although they will give you a
better idea of relative volume levels if you have multiple sources, and
depending on your exact setup and mic they will reduce echo or noise. Your
voice will sound a little different in the headphones than you are used to, but
there is no lag, and you get used to it. Having the audio in your headphones
stops you shouting which people tend to do with headphones as they cannot hear
themselves and compensate. A dynamic mic like the Shure is also fine for
recording with speakers even without cancellation, that is a normal stage
recording setup that they are often used for, ideally with the speakers at 65
degrees behind the mic as that is the zone of least sensitivity. I may well set
up some speakers later; the EVO4 has line out for speakers too. It is less
clear where to put the speakers on the desk though.
You really want a mic “boom stand” with this setup so you can move the mic out
of the way, and then place it back in the right place, as mic placement is
important. I had no idea about stands and got the Neewer
NB-35 which is
very cheap, and it does the job but it is a bit annoying as the part that holds
the mic is hard to keep at the right angle, and the whole thing moves in a
slightly annoying way. I may try a different one.
I originally got the Audio Technica
M30x
headphones. These are not too expensive, and good quality closed ear
headphones, which block out external noise well. I did find that wearing them
for long periods made my ears hot and slightly squashed and they are not great
after an hour or so. I ended up getting open backed, around the ear headphones,
Sennheiser
HD600 which are way more comfortable to wear for long periods, and sound
great. As they aren’t closed, other people could hear you so you wouldn’t wear
them travelling or in a shared office, but if you have your own room to work in
this design works really well, if you don’t want total sound isolation and
noise cancellation (you can hear the doorbell ring, which is useful). You also
can hear yourself speak, although I do like a little microphone mixed in; you
could use these with any kind of microphone without a mixer, and some come with
built in mics.I tested recording while having music playing in the headphones,
and with the Shure mic the recording level even with quite loud music is
negligible with your head in the normal direction; if you point your ears at
the mic it clearly picks up the sound. With a less directional mic such as the
one in the webcam it picks up a quite a bit of the noise though.
Overall I would say that with a dynamic microphone you get a lot more
flexibility in your headphone options. For recording something offline I would
probably use the closed ear headphones or not listen at all during the
recording (the EVO4 can show mic line level). For talking to other people and
daily use the open back headphones are so much more comfortable that they make
a lot of sense, and you can just switch from listening to music to making calls.
I didn’t make any effort to choose portable equipment, as this is lockdown, but
other than the mic stand it is all relatively portable equipment. The EVO4 can
be plugged into an iPod with USB C, or an iPhone if you have the Lightning to
USB3 Camera
Adapter
which despite its name is a generic USB3 adapter that accepts input
power over another lightning port to power external devices that need
additional power that the phone won’t provide. I tested recording and playback
on my phone with this adapter and it worked fine.
The best place I have found for buying audio equipment, other than ordering
direct from the manufacturer, is
Thomann. They are a German family firm
but with a global online shop, and deliver fast and efficiently to the UK, and
their prices are a lot lower than Amazon.
Comparing the options
Below is a video of using internal camera and webcam, and internal mic, webcam
mic, airpods and the Shure mic. I used the Zoom cloud recording, so this gives
an idea of what someone would see and hear at the other end of a call with me,
rather than the best quality for local recording. Note that I had the window
open and a motorbike goes past a couple of times, but sadly not while I was
using each microphone, but I did type on the keyboard so you can hear what some
non directional noise pickup is like. Overall the audio quality and resistance
to noise pickup for the Shure SM57 is substantially better than any of the
other options. So be nice to your co-workers and improve your audio.
Linux
I haven’t yet tested any of this equipment on Linux. I use my Linux machines as
servers not desktop machines at present. The EVO4 audio is a standard USB audio
device so should just work, and I think the Logitech cameras in base settings
are, but there may well be no control of settings, probably including crop, as
this is maybe not standard, I am not entirely sure. Probably best to check.
Is it worth it?
Well, it is not necessary. As I spend a lot of time on calls and do quite a few
conference talks that will all be online for at least the next year or so, I think
improving the quality is worth it. The differences are noticeable as you can see
from the recordings. Audio quality makes a lot of difference to meetings, and I
would make that a priority if you want to work on something. Supply chains should
get better over the next few months so it should get easier to find more choices.
Next weekend is Fosdem, the largest open source event in
Europe. A lot of people will no doubt be coming for the first time, or thinking
about coming another year, so I thought it might be helpful to explain what it
is. Fosdem is not really like any other event, so Americans in particular find
it confusing, thinking it might be like OSCON or something. It is not. Of US
events I know, it is perhaps most like All Things Open, but it really is a
different thing. My qualifications for writing this are that I have been on and
off since about 2004. I worked there a few years, back when Greenpeace ran the
conference WiFi, before Cisco took over, and I have spoken once.
The first practicality is you notice you don’t have to register, or indeed pay.
You should however donate (on site) if you can afford it, although they will
try to give you a really ugly t-shirt if you do. Most people do not donate, so
the conference relies on volunteers, the Université libre de Bruxelles which
gives the space, and, increasingly, corporate sponsors. The next practicality
is where to stay. The location is not very central, and while there is a tram
link it can get extraordinarily full. The best plan is to either stay within
walking distance, or to stay near the start of the tram line, which is near St
Catherine in the centre of Brussels. You can also use taxi/Uber but the sheer
number of people trying to get to and from the location can mean delays.
Brussels is one of my favourite cities in Europe, and along with my friends who
live there, one of the reasons I usually decide to attend. I highly recommend
you spend some time visiting the city. It is February though, so bring hat,
gloves and warm clothes. Some years it has been snowy and the hills get
slippery so be careful walking around, and allow extra time.
The next practicality is that this conference is overwhelmingly attended by
white men. Most tracks will not have any women speakers. We know tech has a
diversity problem, but it is really in your face here more than other places.
Since 2016 there has at least been a code of
conduct after Sarah Mei wrote
about it in
2015. Richard
Stallman attended as recently as 2016. Sarah’s piece says it “feels like 2007”,
and this is changing very slowly.
Fosdem started as a developer meetup place, where distributed communities would
meet to hack on things, and talk about what they have done. So everything is
divided by project like grouping. There are a large number of rooms for talks,
but not enough for all the diversity of modern open source, so some years
projects like Perl that always used to have Fosdem community meetings don’t get
a room, and things get grouped where they used to be split, like “small
languages” or “desktop”. From an audience point of view thats better, and the
community meetings do tend to happen, in the hacking rooms, over meals and so
on. The traditional thing to do is sit in one room all day, but of course lots
of people are interested in learning about new things and want to wander
around. And some things are massively popular and in smallish rooms (most rooms
are smallish), such as the Go room in recent years.
So did fosdem decide
to give away deodorant yet, or is it still the same ol thing
So the talk you want to go to might well be full. Full means full, if the sign
is on the door it means you won’t get in. Remember all the talks are recorded
and streamed, with AV team is pretty amazing. Years ago only some of the rooms
were recorded, but now you won’t miss them. So have a backup plan. I remember a
particularly enjoyable we can’t get into the Go devroom meeting with Jaana and
others one year. Overall my strategy is generally to go to a few things at
random that might be interesting, maybe target a few specific ones that I
really want to go to (and go early maybe for the previoustalk) but not regret
if I can’t get in, and spend most of the time talking to people. The random
things can be great, that is how I started working on NetBSD and rump kernels,
after going to a talk pretty much because I thought a talk about testing
kernels might be interesting. You never know what paths you might go down in
future.
Note there is a growing Fringe of events
around Fosdem, both before, after and during. No dount, like with the Edinburgh
Festical, the Fringe will soon dwarf the original event.
The whole event is really hectic, and there are going tobe maybe 6,000 people
there, maybe it is more. This gets overwhelming, so take time out for yourself.
I am only planning to attend on Saturday this year, and just to chill out in
Brussels on Sunday.
Fosdem has a strong culture of open source as freedom and as a political
statement, and there is widespread antipathy to corporate open source. For a
long time there was no real sign of the larger tech companies, but this has
changed in recent years, with Google and AWS sponsoring this year as is the
CNCF, and visible presence of more corporate and industry rather than
grassroots open source. You will meet people who don’t like this, don’t like
permissive licenses, and might object to your company’s open source policies.
In many ways this feels kind of refreshing
Food is very important. Talks run all day, so you need to plan some time for
lunch. The quickest thing is the baguettes that are available at various
places, eg downstairs back of Jansson. They are very efficient about dispensing
these fast. There isn’t much choice. There are food trucks out front, with huge
queues at lunchtime. I usually go down the road to Le Pain Quotidian (eat in or
take away) in the small cluster of shops down the road. That is busy but less
so. There is really not much else around this area.
Coffee is important too. There is a GitHub sponsored coffee stall that is good,
but it is free so the queue tends to be very long. The next best coffee is at
the cafeteria. Le Pain Quotidian does coffee too. If you want tea, on Saturday
this year OpenUK are serving tea and biscuits and Brexit commiseration on their
stand.
Beer is a fixture at Fosdem. Belgium makes some of the finest beers in the
world, and some ok ones too. Beers are sold at several points in the venue, and
it is common to take them to talks and so on. Beware most Belgian beers are
strong. Also the kriek they sell at the venue is terrible, even though Belgium
makes some amazing examples of this beer style. There is a pre-conference “beer
event” on Friday, I haven’t even tried to go for many years, even though they
take over an entire street it is too crowded to be enjoyable or find anyone you
want to talk to. Yes, there are a lot of alcohol focused events, and events in
bars which could be offputting if you don’t drink.
Brussels is a lovely city. The architecture is beautiful, both the old as
exemplified by Grand Place which is magical in the evening, and the art deco
gems, such as the Musical Instrument Museum, once a shop, and the diversity
everywhere. It is said that there is a rule about not copying buildings,
although I am not sure this is really the cause, but Belgium does not have
terraces of identical houses, but every building is totally different. The
Belgians are also as eccentric as the British, if not more so. Also don’t miss
the Galaries Royal St Hubert, the first glazed shopping street in Europe, from
1847.
Perhaps my favourite area are the parts between Sablon, which has a grand
antique market and excellent chocolate shops, and the Marché aux Puces, the
flea market which is full of junk. In between are several streets lagely filled
with antique shops, selling midcentury furniture, and well everything. Some are
huge inside full of things and stuff of every kind just jumbled up anyhow.
There are often amazing window displays like the one below.
Food in Brussels is really good, although Fosdem is not always the best time to
eat as you are often with indeterminate amounts of people and getting
reservations, which are often needed on Friday and Saturday nights, is hard.
Also most places are small. Brussels is very international, and all kinds of
food are available there. While most people just think that Belgian food is
frites with mayonnaise and waffles, but there is both French and Flemish food
that are traditional, and great seafood, not just mussels. The local beer is
lambic beer, the sourdough of beer styles made with wild yeast that is only
made in the region. Cantillon is one of the best, and has an amazing museum in
the working brewery in Brussels. This styleof beer is sour, but it is
absolutely delicious. If you love this style, Moeder Lambic is a great place to
try it. There have been a number of new breweries open recently, de la Senne is
excellent and available in good bars.
This year, the Friday night before Fosdem is Brexit. Brussels has a large UK
community, and Fosdem always has a large UK contingent, with whole Eurostar
trains being filled on Friday evening usually. So be nice to any of us you see.
So, yeah, that is Fosdem. Unique. Could be better. Enjoy Brussels.
Illustration from Paul Klee, Pedagogical Sketchbook, 1925
I have been reading a lot of papers on linear types recently. Originally it was
to understand better why Rust went down the path it did, but I found a lot more
interesting stuff there. While some people now are familiar with linear typesas
the basis for Rust’s memory management, they have been around for a long time
and have lots of other potential uses. In particular they are interesting for
improving resource allocation in functional programming languages by reusing
storage in place where possible. Generally they are useful for reasoning about
resource allocation. While the Rust implementation is probably the most widely
used at present, it kind of obscures the underlying simple principles by adding
borrowing, so I will only mention it a little in this post.
So what are linear types? I recommend you read “Use-once” variables and linear
objects: storage management, reflection and
multi-threading by Henry
Baker, as it is the best general overview I have found. The basic idea is
extremely simple, linear variables can only be used once, so any function that
receives one must either return it, or pass it to another function that
consumes it. Using values only once sounds kind of weird and restrictive, but
there are some ways it can be made easier. Some linear types may have an
explicit copy operation to duplicate them, and others may have operations that
return a new value, in a sequential way. For example a file object might have a
read operation that returns the portion read and a new linear object to read
for the next part, preserving a functional model: side effects are fine if you
cannot reuse a variable. You won’t really recognise much of the Rust model
here, as it allows borrows, which presents a much less austere effect. It does
all sound fairly odd until you get used to it, even though it is simpler than
say monads as a way of sequencing. Note also that there are related affine
types,where you can use values zero or one times, so values can be discarded,
and other forms such as uniqueness types, and many other fun variants in the
literature.
Memory is probably the easiest way to understand the use cases. Think about
variables as referring to a chunk of memory, rather than being a pointer.
Memory can be copied, but it is an explicit relatively costly operation (ie
memcpy) on the memory type, so the normal access should be linear with
explicit copying only if needed. Because the value of the memory may be changed
at any time by a write, you need to make sure there are not multiple writers or
readers that are not reading in a deterministic order. Rust does this with
mutable borrows, and C++ has a related thing with move semantics.
Rust’s borrow checker allows either a single reference with read and write
access, or multiple readers when there is no write access. Multiple readers is
of course not a linear access pattern, but is safe as multiple reads of an
immutable object return the same value. The complexity of the borrow checker
comes from the fact that objects can change between these states, which
requires making sure statically that all the borrows have finished. Some of the
use cases for linearity in functional languages relate to this, such as
efficiently initialising an object that will be immutable later, so you want
linear write access in the initialisation phase, followed by a non linear read
phase. There are definitely interesting language tradeoffs in how to expose
these types of properties.
Anyway, I was thinking about inter process communication (IPC) again recently,
in particular ring buffer communication between processes, and it occured to me
that this is another area where linearity is a useful tool. One of the problems
with shared memory buffers for communication, where one process has read access
and the other write access for each direction of communication is that the
writing process may try to attack the reader by continuing to write after
reading has started. The same issue applies for userspace to kernel
communication, where another userspace thread may write to a buffer that the
kernel has already read. This is to trigger a time of check time of use
(toctou) attack, for example if there is a check that a size is in range, but
after that the attacker increases it. The standard defence is to copy buffers
to a private buffer, where validation may happen undisturbed. This of course
has a performance hit, but many IPC implementations, and the Linux kernel, do
this for security reasons.
Thinking about toctou as a linearity problem, we can see that “time of check”
and “time of use” are two different reads, and if we treat the read buffer as a
linear object, and require that its contents are each only read once, then time
of check and time of use cannot be different. Note of course that it does not
matter exactly which version gets read, all that matters is that it is a
consistent one. We have to remember the value of the part we check and keep
that for later if we can’t use it immediately. So linear read has its uses. Of
course it is not something that programming languages give us at present,
generally a compiler will assume that it can reload from memory if it needs to.
Which is why copying is used; copying is a simple linear operation that is
available. But there are often cases where the work being done on the buffer
can be done in a linear way without copying, if only we had a way of telling
the compiler or expressing it in the language.
Overall, I have found the linear types literature helpful in finding ways to
think about resource allocation, and I would recommend exploring in this space.
I am not going to talk about most of it, just a few small points that
especially interest me right now, which are definitely not the most important
things from the outage point of view. This post got a bit long so I split it
up, so this is part one.
Fuzz testing has been around for quite some time. American Fuzzy
Lop was released in 2013, and was the first
fuzzer to need very little configuration to find security issues. This paper
on mutational
fuzzing is a
starting point if you are interested in the details of how this works. The
basic idea is that you start with a valid input, and gradually mutate it,
looking for “interesting” changes that change the path the code takes. This is
often coverage guided, so that you attempt to cover all code paths by changing
input data.
Fuzz testing is not the only tool in the space of automated security issue
detection. There is traditional static analysis tooling, although it is
generally not very efficient at finding most security issues, other than a few
things like SQL injection that are often well covered. It tends to have a high
false positive rate, and unlike fuzz testing will not give you a helpful test
case. Of course there are many other things to consider in comprehensive
security testing, this list of considerations is very
useful. Another technique is automated variant
analysis, taking an existing issue and finding other cases of the same issue,
as done by platforms such as Semmle.
Fuzzing as a service is available too. Operationally fuzzing is not something
you want to run in your CI pipeline, as it is not a test that finishes, it is
something that you should run continuously 24⁄7 on the latest version of your
code to find issues, as itstill takes a long time to find issues, and is
randomised. Services include Fuzzbuzz a fairly new
commercial service (with a free tier) who are very friendly, Microsoft
Security Risk
Detection and
Google’s OSS-Fuzz for open source
projects.
As Cloudflare commented “In the last few years we have seen a dramatic increase
in vulnerabilities in common applications. This has happened due to the
increased availability of software testing tools, like fuzzing for example.”
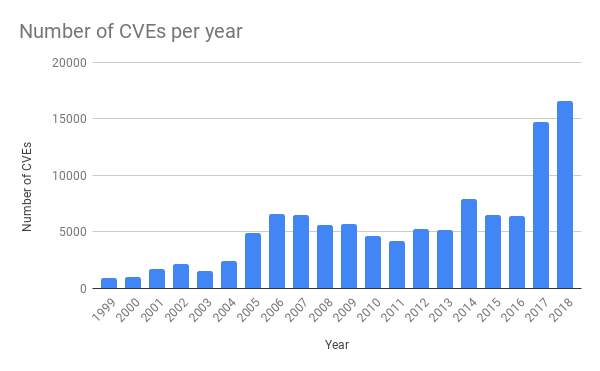
Some numbers give an idea of the scale: as of January 2019, Google’s
ClusterFuzz has found around 16,000 bugs in Chrome and around 11,000 bugs in
over 160 open source projects integrated with OSS-Fuzz. We can see the knock on
effect on the rate of CVEs being reported.
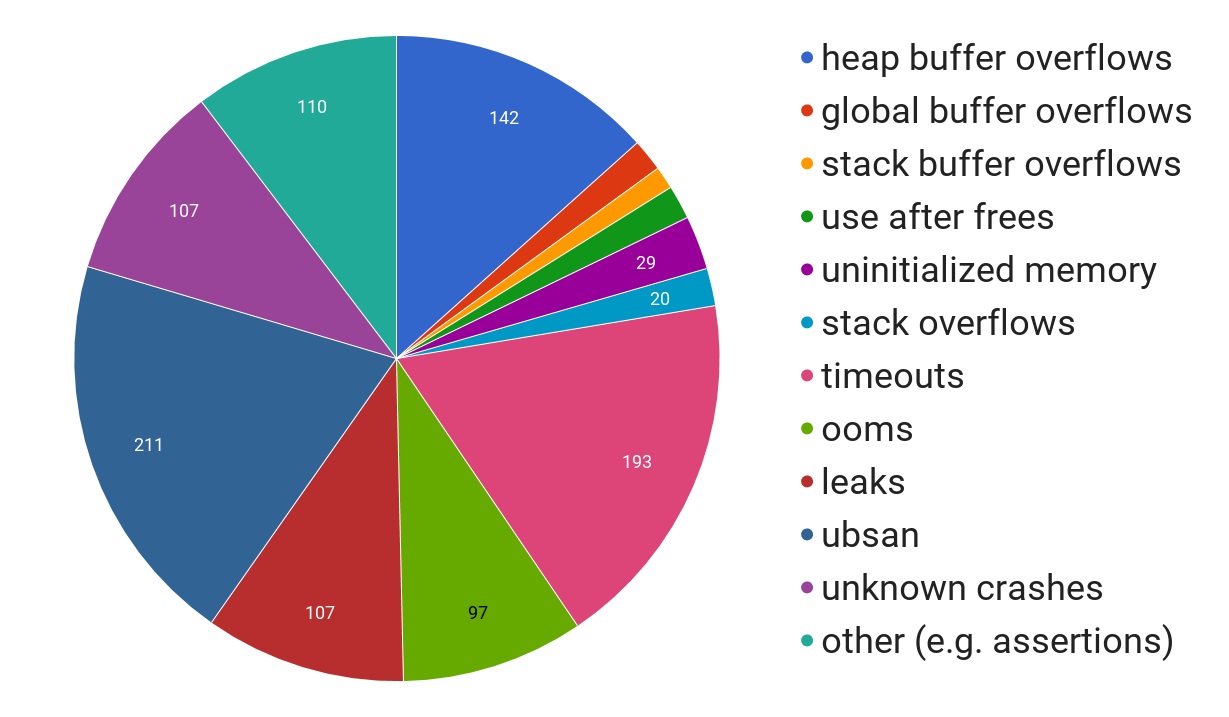
If we look at the kinds of issues found, data from a 2017 Google blog
post the breakdown is interesting.
As you can see a very large proportion are buffer overflows, manual memory
management issues like use after free, and the
“ubsan“
category, which is all the stuff in C or C++ code that if you happen to write
it the compiler can turn your program into hot garbage if it feels like it.
Memory safety is still a major cause of errors, as you can see if you follow
the @LazyFishBarrel twitter account. Note
that the majority of projects are still not running comprehensive automated
testing for these issues, and this problem is rapidly increasing. Note that
there are two factors at play: first, memory errors are an easier target than
many other sorts of errors to find with current tooling, but second there is a
huge codebase that has huge numbers of these errors.
Microsoft Security Response Center also just released a blog
post with some more numbers. While ostensibly about Microsoft’s
gradually increasing coding in Rust, the important quote is that “~70% of the
vulnerabilities Microsoft assigns a CVE each year continue to be memory safety
issues”.
In my talk at Kubecon I touch on some of these issues with C (and to some
extent C++) code. The majority of the significant issues found in the CNCF
security audits were in C or C++ code, despite the fact there is not much of
the is code in the reviewed projects.
Most of the C and C++ code that causes the majority of open source CVEs is
shipped in Linux distributions. Linux distros are the de facto package manager
for C code, and C++ to a lesser extent; neither of these langauges have
developed their own language specific package management yet. From the Debian
stats, of the billion or so lines of code,
43% is ANSI C and 24% is C++ which has many of the same problems in many
codebases. So 670 million lines of
code,
in general without enough maintainers to deal with the existing and coming
waves of security issues that fuzzing will find. This is the backdrop of
increasing complaints about unfixed CVEs in Docker containers, where these tend
to me more visible due to wider use of scanning tools.
Is it worth fuzzing safer languages such as Go and Rust? Yes, you will still
find edge conditions, and potentially other cases such as race conditions,
although the payoff will not be nearly as high. For C code it is absolutely
essential, but bugs and security issues are found elsewhere. Oh and fuzzing is
fun!
My view is that we are just at the beginning of this spike, and we will not
just find all the issues and move on. Rather we will end up with the Linux
distributions, which have this code will end up as toxic industrial waste
areas, the Agbogbloshie
of the C era. As the incumbents, no they will not rewrite it in
Rust, instead smaller more nimble
different types of competitor will outmanouvre the
dinosaurs. Linux distros
generally consider that most of their role is packaging not creation, with a
few exceptions like Systemd; most of their engineering work is in the long term
support business, which still pays well despite being increasingly out of step
with how non-C software is used, and how cloud deployments work, where updating
software is part of normal life, and five or ten year software lifetimes
without updates are not the target. We are not going to see the Linux distros
work on solving this issue.
Is this code exploitable? Almost certainly yes with sufficient effort. We
discussed Thomas Dulien’s paper Weird machines, exploitability, and provable
unexploitability at the Säntis Systems
Summit
recently, I highly recommend it if you are interested in
exploitability. But overall, proving code is not exploitable is in general not
going to be possible, and attackers always have the advantage. Sure they will
pick the easiest things first, but most attacks are automated now and attacking
scales well. Security is risk management, but with memory safety being a
relatively easy exploit in many cases, it is a high risk. Obviously not all
this code is exposed to attackers via network or attacker supplied data,
especially in containerised environments, but some is, and you will spend
increasing amounts of time working out what is a risk. The sheer volume of
security issues just makes risk management more difficult.
If you are a die hard C hacker and want to remain one, the last bastion of C is
of course OpenBSD. Throw up the pledge barricades, remove anything you can,
keep reviewing. That is the only heroic path left.
In the short term, start to explore and invest in ways to replace every legacy
C dependency you are currently using. Write a deprecation roadmap. Cut down
your dependencies on Linux distributions. Shift to memory safe languages
everywhere, and if you use C++ make sure you only use the safer subset. Look to
smaller more nimble Linux distributions that start shipping memory safe code;
although the moves here have been slow so far, you only need a little as once
distros stop having to be C package managers they can do a better job of being
minimal userspaces. There isn’t much code you really need to run modern
applications that themselves do not have many C dependencies, as
implementations like LinuxKit show. If you just sit on top of the kernel, using
its ABI stability guarantees there is little you need to do other than a little
configuration; well other than worry about the bugs in a kernel written in … C.
Memory unsafe languages are not going to get better, or safe. It is time to move on.